精度调优
您可以通过对比迁移后模型和PyTorch原始模型的执行结果,确保迁移模型的功能正确性。这里推荐两种方式进行比较:
方式一:加载PyTorch的pth文件进行精度比较,使用该方式可以对每个网络层输入输出值进行比较,如果出现精度异常时可快速定位出精度异常的网络层。
方式二:基于TroubleShooter工具进行精度比较,使用该方式不需要用户提供pth文件(依赖环境安装PyTorch库),可进行最终网络输出值的比较。
当前两种工具都能实现网络逐层精度对比功能,除了使用接口上的差异,主要区别在于方式一的初始权重是加载相同PyTorch模型的权重,而方式二是工具中自动生成相同随机初始权重。如果网络精度异常仅出现在特定权重场景,建议使用方式一的工具进行定位。
方式一 加载PyTorch的权重进行精度比较
该方法大致可分为以下几个步骤:
步骤 1:确保网络输入完全一致(可以使用固定的输入数据,也可调用真实数据集)。
步骤 2:确保执行推理模式。
model = LeNet()
model.eval()
由于框架随机策略以及各自内置随机数生成算法的实现存在差异,所以即使用户配置相同的随机种子,两个框架生成的随机数并不一致(详情请参考MindSpore与PyTorch随机数策略的区别)。同理,带有随机性的接口,如nn.dropout,当配置概率不为0或1时,即使输入一致,由于内置随机数逻辑差异,两个框架得到的输出结果并不一致。通过配置网络为推理模式则可排除这方面随机性的影响。
步骤 3:确保网络权重的一致性。
由于目前MindSpore随机策略与PyTorch随机策略有所不同(正在优化中),即使网络层初始化策略与算法完全一致,也无法保证权重值一致。此时可以先保存PyTorch的网络权重,再加载至MindTorch迁移模型的权重中:
1). 在PyTorch原始脚本中保存网络权重至本地(如果已有模型提供下载的pth文件可跳过该步骤)。
import torch
torch.save(net.state_dict(), 'pytorch.pth')
2). 将PyTorch权重加载至MindTorch迁移模型中。
在MindTorch迁移网络脚本中加载 1) 中保存的pth,即可将PyTorch的权重加载到迁移模型中,从而保证网络权重的一致性。
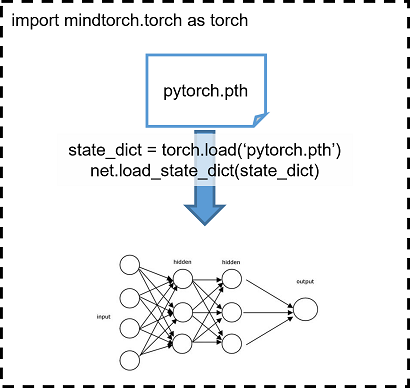
import mindtorch.torch as torch
net.load_state_dict(torch.load('pytorch.pth'))
如果使用mindtorch 0.3之前的版本,可参考FAQ中的方法来加载PyTorch权重文件。
步骤 4:分别将PyTorch和MindTorch的模型推理结果打印出来进行比较,如果比较结果精度误差在1e-3范围内则表示迁移模型精度正常。
步骤 5:打印网络逐层信息协助定位精度异常。
当出现网络输出误差过大情况,可以结合信息调试工具(debug_layer_info),检查各网络层输入输出的信息,便于快速定位导致精度异常的网络层,提升精度调试分析效率。同时也可以在动态图模式下基于关键位置添加断点,逐步缩小范围,直至明确误差是否合理。
1). 收集PyTorch网络逐层信息,使用样例如下:
import torch
from mindtorch.tools import debug_layer_info
...
net = Net()
net.load_state_dict(torch.load('pytorch.pth'))
net.eval()
debug_layer_info(net, frame='pytorch') # PyTorch原始脚本需配置frame='pytorch'
for X, y in train_data:
pred = net(x)
...
exit() # Just compare the first step
2). 收集MindTorch网络逐层信息,使用样例如下:
import mindtorch.torch as torch
from mindtorch.tools import debug_layer_info
...
net = Net()
net.load_state_dict(torch.load('pytorch.pth')) # 依赖PyTorch,未安装时需加载'msa.pth'.
net.eval()
debug_layer_info(net)
for X, y in train_data:
pred = net(x)
...
exit() # Just compare the first step
用户只需要分别在MindTorch或PyTorch模型实例化对象后调用debug_layer_info接口,即可输出模型内各层的输入输出信息(更多可选配置属性可参考信息调试工具)。推荐在第一个step结束时直接exit()程序,分别捕获MindTorch和PyTorch第一个step的推理信息并进行比较就可以确定精度异常的网络层。
例:以ModelZoo中的AlexNet网络为例:
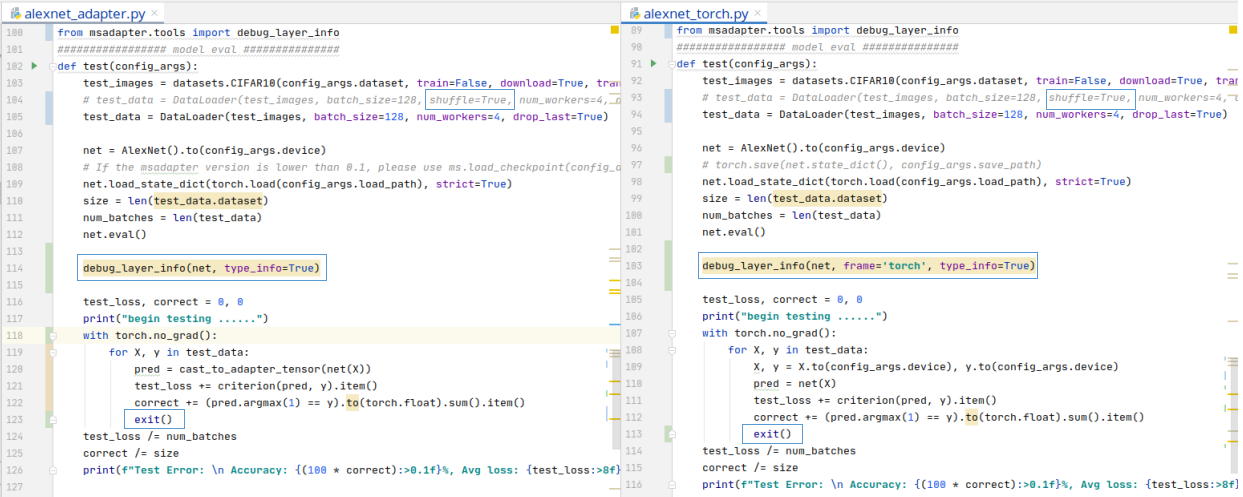
注意,用例中为保障输入数据一致性,需要取消数据的shuffle行为,并加载相同的pth文件,保证权重初始化的一致性。
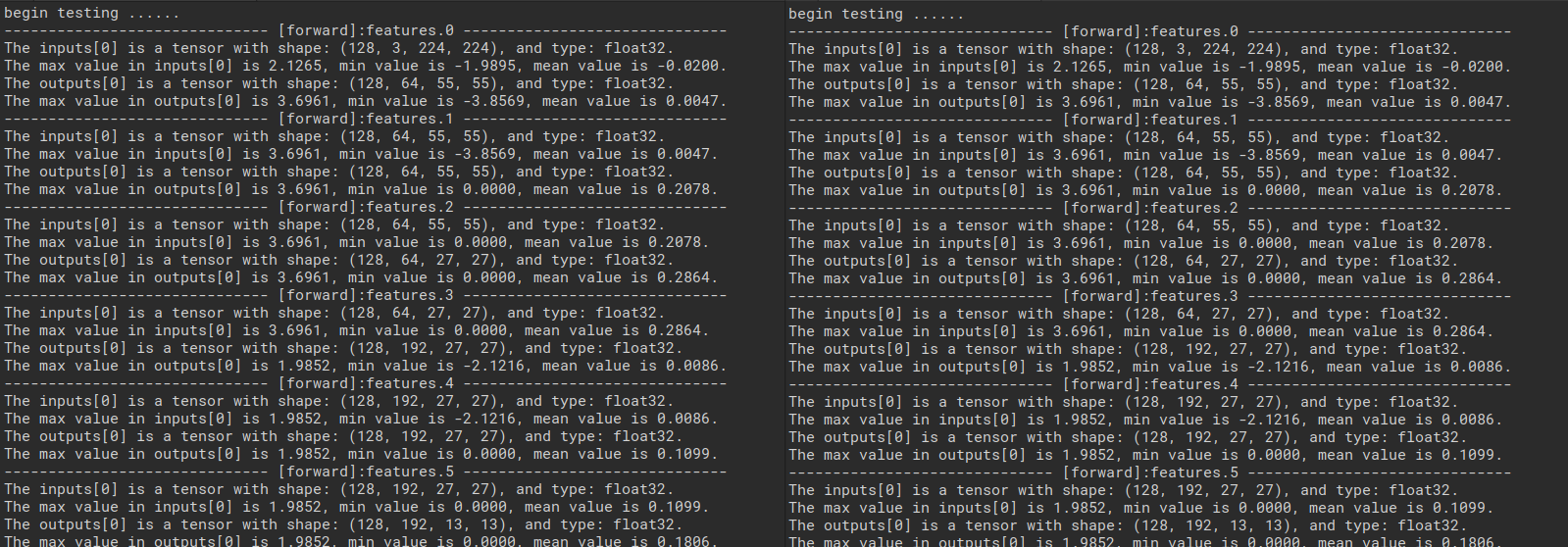
3). 网络逐层信息比较。
使用文件对比工具可以对比每个网络层的输入输出和权重,初步确定精度异常层后再细化定位具体接口,可提升调试效率。
网络权重信息对比:

注:BN层中的running_mean和running_var等buffer信息在MindTorch侧会在parameters中打印,而PyTorch侧会在buffers中打印。
网络逐层信息对比:
方式二 基于TroubleShooter工具进行精度比较
TroubleShooter工具提供API级别自动化比较功能,可实现对PyTorch和MindTorch网络正、反向API级别输入、输出数据的自动保存以及对比功能。
需要说明的是,TroubleShooter工具提面对MindSpore网络开发提供了丰富了调试功能,对于MindTorch迁移场景目前仅支持API级别网络结果自动比较功能。
版本配套说明
| MindTorch版本 | TroubleShooter版本 |
|---|---|
| 0.3 | 1.0.17 |
| 0.2.1 | 1.0.16 |
安装TroubleShooter工具
pip安装:
pip install troubleshooter -i https://pypi.org/simple
源码安装:
git clone https://gitee.com/mindspore/toolkits.git
cd toolkits/troubleshooter
bash package.sh
pip install output/troubleshooter-*-py3-none-any.whl -i https://pypi.org/simple
使用TroubleShooter工具
保存数据
数据保存共有两个主要步骤:
1). 初始化dump功能。
调用troubleshooter.migrator.api_dump_init()接口对MindTorch网络和PyTorch网络执行初始化,指定输出路径。如果需要保存反向数据,需要指定retain_backward参数为True;如果需要比较网络state_dict中的内容,需配置compare_statedict=True。详细请参考troubleshooter.migrator.api_dump_init()接口说明。
2). 设置dump范围。
在需要进行精度定位的代码上下调用troubleshooter.migrator.api_dump_start()和troubleshooter.migrator.api_dump_stop。troubleshooter.migrator.api_dump_start()还可以指定dump的接口名、数据种类等,详细请参考接口参数说明。
下面以AlexNet的训练代码为例,分别在PyTorch和MindTorch的网络训练脚本中按顺序调用troubleshooter相关接口并运行:
PyTorch代码中使用样例:
import torch
import troubleshooter as ts
...
def train():
...
net = AlexNet()
ts.migrator.api_dump_init(net, './pt_res', retain_backward=True, compare_statedict=True) # 初始化PyTorch dump结果输出的文件位置,指定需要dump的内容
ts.migrator.api_dump_start() # 开启数据dump
for X, y in train_data:
output = net(X, y) # 开始训练
...
ts.migrator.api_dump_stop() # 停止数据dump
exit() # 推荐只比较第一个step
MindTorch代码中使用样例:
import msadapter.pytorch as torch
import troubleshooter as ts
...
def train():
...
net = AlexNet()
ts.migrator.api_dump_init(net, './ad_res', retain_backward=True, compare_statedict=True) # MindTorch dump结果输出的文件位置,指定需要dump的内容
ts.migrator.api_dump_start() # 开启数据dump
for X, y in train_data:
output = net(X, y) # 开始训练
...
ts.migrator.api_dump_stop() # 停止数据dump
exit() # 保持一致,只比较第一个step
当执行成功后日志会显示dump数据保存的路径:

其中,PyTorch 生成的目录结构如下:
output_path # 输出目录'./pt_res'
└── rank0
├── torch_api_dump # npy数据目录
├── torch_api_dump_info.pkl # dump的info信息
├── torch_api_dump_stack.json # dump的堆栈信息
└── pt_net.pth # 存储的网络 state_dict 中的内容(仅在compare_statedict 为 `True`时保存)
MindTorch 生成的目录结构如下:
output_path # 输出目录'./ad_res'
└── rank0
├── mindtorch_api_dump # npy数据目录
├── mindtorch_api_dump_info.pkl # dump的info信息
├── mindtorch_api_dump_stack.json # dump的堆栈信息
└── ad_net.pth # 存储的网络 state_dict 中的内容(仅在compare_statedict 为 `True`时保存)
比较结果
调用troubleshooter.migrator.api_dump_compare()接口比较上一步保存的数据。
import troubleshooter as ts
if __name__ == "__main__":
ts.migrator.api_dump_compare('./pt_res/', './ad_res', equal_nan=True)
该接口的其他参数和详细使用方法见troubleshooter.migrator.api_dump_compare文档。
注意:需要在main函数中调用该接口。
运行上述比较脚本后会根据保存数据内容不同,获得不同的比较内容:
正向输入输出的对比:

设置
troubleshooter.migrator.api_dump_init(compare_statedict=True)时,结果中包含网络中可学习参数的对比:
设置
troubleshooter.migrator.api_dump_init(retain_backward=True)时,结果中包含反向输入输出的对比:
查询接口调用栈
在指定生成的dump目录中找到.json文件,用上一步比较结果中有差异的接口名作为关键字在文件中检索相应的调用栈信息,从而便于进一步定位和修改。
如果在使用过程中出现debug_layer_info工具或TroubleShooter工具相关问题,可以通过ISSUE反馈。