常见问题
Q. 目前支持了哪些接口的功能呢? A: 可以在torch接口支持列表和TorchVision接口支持列表中查看接口支持情况。
Q:设置mindspore.set_context(mode=context.GRAPH_MODE)后运行出现类似问题:
“Tensor.add_” is an in-place operation and “x.add_()” is not encouraged to use in MindSpore static graph mode. Please use “x = x.add()” or other API instead。
A:目前在设置GRAPH模式下不支持原地操作相关的接口,需要按照提示信息进行修改。需要注意的是,即使在动态图(PyNative)模式下,原地操作相关接口也是不鼓励使用的,因为目前在MindTorch不会带来内存收益,而且会给反向梯度计算带来不确定性。建议将原地操作接口替换成非原地操作接口。
Q:运行代码出现mindtorch无某个接口的相关报错信息:
AttributeError: module ‘mindtorch.torch’ has no attribute ‘xxx’。
A:首先确定’xxx’是否为torch 1.12版本支持的接口,PyTorch官网明确已废弃或者即将废弃的接口和参数,MindTorch不会兼容支持,请使用其他同等功能的接口代替。如果是PyTorch对应版本支持,而MindTorch中暂时没有,欢迎参与MindTorch项目贡献你的代码,也可以通过创建任务(New issue)反馈需求。
Q:为什么TensorDataset返回值为numpy.ndarray类型?
A:为了加速数据处理流程以及避免在GPU/Ascend中SyncDeviceToHost失败,TensorDataset返回值会被转换为numpy.ndarray类型。如果您结合DataLoader使用则无需关注返回值类型,如果您单独调用该接口则需要手动将输出转换为Tensor类型。
dataset = TensorDataset(all_input_ids)
for data in dataset:
data = torch.tensor(data)
Q:mindtorch.torch.__version__对应版本是多少?具体怎么使用?
A:和MindTorch接口对标的策略相同,mindtorch.torch.__version__当前对应于1.12.1。使用方法上,在动态图(PyNative)模式下, 保持与PyTorch一样的使用方法及功能;在静态图(Graph)模式下,需要在图外(@ms.jit的作用域之外或者nn.module.forward之外)使用,才能保证功能的正确性。
Q:静态图模式下不支持torch.dtype的is_floating_point/is_complex/is_signed方法?
E # 1 In file testing/ut/pytorch/torch/test_dtype.py:15
E if x_dtype.is_floating_point:
E ^
E
E ----------------------------------------------------
E - C++ Call Stack: (For framework developers)
E ----------------------------------------------------
E mindspore/ccsrc/pipeline/jit/ps/static_analysis/prim.cc:1590 GetEvaluatedValueForNameSpace
A:当前图模式下暂不支持取dtype属性方法,可以用以下写法替代:
from mindtorch.torch.common.dtype import all_float_type, all_signed_type, all_complex_type
# Replace x_dtype.is_floating_point
if x_dtype in all_float_type:
...
# Replace x_dtype.is_signed
if x_dtype in all_signed_type:
...
# Replace x_dtype.is_complex
if x_dtype in all_complex_type:
...
Q: torch.set_default_dtype和torch.set_default_tensor_type设置的dtype类型会影响哪些接口的输出类型?
A:目前对函数式接口arange,bartlett_window, empty, empty_strided, eye, full, hamming_window, hann_window, kaiser_window, linspace, logspace, ones, rand, randn, range, zeros的结果类型会产生影响,以及使用这些接口的其他数据,例如,nn.Conv2d的weight;暂不支持对复数类型的影响。
Q: 项目更名为MindTorch后,之前已迁移至MSAdapter的网络脚本,怎么快速地迁移到MindTorch上?
A:项目更名之后,使用上主要的改变,是从import msadapter.pytorch变更为import mindtorch.torch,以及从import msadapter.torchvision变更为import mindtorch.torchvision。对于该变更,在mindtorch/tools目录下,提供了replace_import_msadapter_to_mindtorch.sh自动化脚本,可以一键化地将相关的import从msadapter切换成mindtorch。
例如有目录文件 /mynet, 执行以下命令即可进行自动替换:
bash replace_import_msadapter_to_mindtorch.sh /mynet
Q: 原始脚本中调用Apex相关接口实现混合精度报错,该怎么适配迁移到MindTorch上?
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
A:Apex是基于PyTorch开发的混合精度训练加速库,未适配其他框架,如果用户想实现混合精度加速,可参考使用混合精度加速训练 章节,调用mindspore.amp.auto_mixed_precision接口实现混合精度训练。
Q: 接口迁移时报错没有某些关键字属性,出现类似报错信息:
TypeError: mean() got an unexpected keyword argument ‘keepdims’
A:PyTorch部分接口的入参有别名的情况。如mean接口,用户指定keepdim与keepdims可以实现等价效果;sort接口,用户指定dim或axis均可以指定轴。针对这类场景当前需要用户修改使用PyTorch官方文档中呈现的关键字属性进行赋值。
Q: 接口迁移时报错入参个数与位置参数个数不一致,出现类似报错信息:
TypeError: addmm_() takes 3 positional arguments but 5 were given
A:PyTorch新版本中存在一些接口和老版本的入参个数不一致的现象,如add, addcmul, addmm等接口,这类老版本的用法在新版本中已废弃。针对这类场景当前需要用户修改使用PyTorch官方文档(1.12.1版本)中呈现的用法。
Q: 自定义Module执行时报错AttributeError:cells?
A:Module继承于mindspore.nn.Cell,有些方法名或属性名已被使用,因此在Module的子类中不能定义名为’cast’的方法,不能定义名为’phase’和’cells’的属性,否则会报错。如该报错示例,在自定义Module中重新定义了cells属性导致报错,用户在自定义子类中使用其他名字即可正常执行。
Q:自定义Module执行时出现类似报错信息:
TypeError: ‘NoneType’ object does not support item assignment
A:请检查自定义Module中是否存在张量对象赋值为类属性的情况,如self.xxx=torch.Tensor(xxx),请确保super().__init__()在此之前被调用。
Q:当使用运行时自动替换导入模块,如何使能一些原生PyTorch的模块功能?
A:可以调用from mindtorch.tools import pytorch_enable接口临时使能原生PyTorch的模块功能,示例如下:
from mindtorch.tools import mstorch_enable
import torch
from mindtorch.tools import pytorch_enable
import torch as pytorch
from mindtorch.tools import mstorch_enable
pytorch.xxx # 调用pytroch原生功能模块
torch.xxx # 调用mindtorch相应模块
Q:程序并未在torch.cuda.set_device指定的卡上执行?:
A:如手动适配-3.1指定执行硬件所示,若mindtorch期望在特定后端(卡)上执行时,需通过mindspore.set_context接口显示指定设备,且暂不支持计算过程中在不同设备间转移Tensor。因此下列PyTorch接口的指定执行设备的功能均暂不生效:
torch.cuda.set_device(device)
module.cuda(device)
tensor.cuda(device)
tensor.to(device)
torch.set_default_device(device)
如果期望实现异构执行功能,可调用Primitive.set_device接口实现,详情请参考Host&Device异构。
Q:Generator相关功能是否支持?:
A:由于框架随机数机制差异,当前暂不支持Generator相关功能,需删除Generator相关接口和参数调用。该功能已经在开发中,下个版本可支持,敬请期待!
Q:自定义算子是否支持自动迁移?:
A: 由于涉及硬件区别,目前自定义操作需适配Ascend硬件自定义算子方式,以及MindSpore自定义算子接入方式。请参阅手动适配-4 自定义操作章节详细描述。
Q:mindtorch 0.3版本之前如何加载PyTorch的权重文件?:
A: 分为两种场景:
场景一: 若执行环境有PyTorch库可直接加载pth。
场景二: 如果最终执行环境无法安装PyTorch库,可参考则需要借助其他已安装PyTorch的环境上进行离线模型转换。可参考下图流程将PyTorch权重加载至MindTorch迁移模型中:
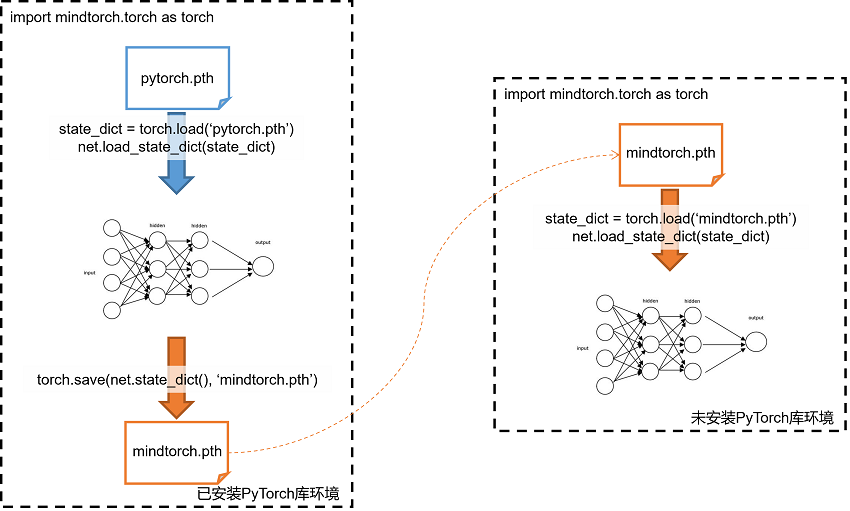
首先在同时安装有PyTorch和MindTorch的环境上执行离线模型转换:
import mindtorch.torch as torch
...
net.load_state_dict(torch.load('pytorch.pth'))
torch.save(net.state_dict(), 'mindtorch.pth')
保存MindTorch对应的pth文件后,可在最终执行环境中加载:
import mindtorch.torch as torch
...
net.load_state_dict(torch.load('mindtorch.pth'))
Q:mindtorch load失败后如何加载PyTorch的权重文件?:
A: 可以考虑直接使用pytorch原生load方式来加载权重文件,然后使用mindtorch.tools中的工具,将pytorch权重文件转换为mindtorch权重文件,具体操作如下:
from mindtorch.module_hooker import torch_enable, torch_pop
from mindtorch.tools import convert_to_ms_tensor
import mindtorch.torch as torch
...
net = model()
pth = 'pytorch.pth'
torch_enable() ##强制使用torch原生load
import torch as pytorch ##导入pytorch,并且不要使用torch命名
state_dict = pytorch.load(pth)
torch_pop() ##恢复使用mindtorch.torch
state_dict = convert_to_ms_tensor(state_dict)
net.load_state_dict(state_dict)
Q:两个Tensor配置同一个Storage对象,修改其中一个后,另一个并未同步修改?:
A: 由于张量存储机制差异,张量/Storage/共享Storage的张量之间并不真实共享存储区,当前通过Storage和张量对象之间建立一一映射关系,来模拟原地修改操作,当对其中一个对象数据进行修改时同步更新映射对象。Storage仅保留对最新相关的张量的映射,所以无法做到一个张量修改,另一个也同时被修改。 如下示例,注意下面用例中Storage与张量之间的映射关系:
from mindtorch.tools import mstorch_enable
import torch
import numpy as np
a = torch.tensor(np.array([1., 2., 3.]))
storage1 = a.storage()
# 此时张量a和storage1相互映射:
# 1) 若原地修改storage1,张量a的取值也被更新;
storage1[2] = 2
assert storage1[2] == a[2] == 2
# 2) 若原地修改张量a,storage1的取值也被更新;
a[2] = 4
a.numpy() #更新后调用a.numpy()或打印等同步操作,确保数据完成同步;
assert storage1[2] == a[2] == 4
b = torch.tensor([], dtype=storage1.dtype)
b.set_(storage1)
# 此时张量a和storage1不再相互映射, 张量b和storage1相互映射:
# 1) 若原地修改storage1,张量b的取值也被更新,但a的取值不会更新;
storage1[2] = 5
assert storage1[2] == b[2] == 5
assert a[2] == 4
# 2) 若原地修改张量b,storage1的取值也被更新,但a的取值不会更新;
b[2] = 6
b.numpy() #更新后调用a.numpy()或打印等同步操作,确保数据完成同步;
assert storage1[2] == b[2] == 6
assert a[2] == 4
# 3) 若原地修改张量a,则storage1和b的取值不会更新;
a[2] == 7
assert storage1[2] == b[2] == 6
# 若期望a的数据也更新为storage1,可手动调用set_方式更新,此时张量a和storage1相互映射, 张量b和storage1不再相互映射::
a.set_(storage1)
assert storage1[2] == a[2] == b[2] == 6
Q:切片等场景不支持numpy数组作为入参?:
A: PyTorch数据存储和numpy数组一致,所以有些场景下可能出现两个库接口相互调用的情况,但MindSpore张量和numpy数组并不共享数据存储,所以在调用numpy接口前需要先调用Tensor.numpy()接口,将张量转换为
ndarray后再调用numpy接口。同理,在调用MindTorch接口前需要先把ndarray类型数组转换为接口官方支持的类型或张量。如:
>>> import torch
>>> import numpy as np
>>> import mindtorch.torch as mstorch
>>> a = np.array([1,2])
>>> b = torch.Tensor(3,4)
>>> b[:,a]
tensor([[ 3.0845e-41, -2.0170e-23],
[ 3.0845e-41, 9.1084e-44],
[ 3.0845e-41, -1.6864e-23]])
>>> c = mstorch.Tensor(3,4)
>>> c[:,a] # 直接传入ndarray类型数组会报错
TypeError: For tuple index, the types only support 'Slice', 'Ellipsis', 'None', 'Tensor', 'int', 'List', 'Tuple', 'bool', but got type 'Array', value: [1 2]
>>> c[:,list(a)] # ndarray类型数组转换为list后可正常执行
Tensor(shape=[3, 2], dtype=Float32, value=
[[ 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00]])
Q:报错不支持<class 'range'>类型的入参?:
A: 当切片或创建Tensor时,传入Python的range对象可能报以下错误:
>>> import mindtorch.torch as mstorch
>>> mstorch.Tensor(range(10)) # 传入range对象会报错
TypeError: For Tensor, data must be a sequence, got <class 'range'>
>>> mstorch.Tensor(list(range(10))) # 转为list类型后可正常执行
Tensor(shape=[10], dtype=Float32, value= [ 0.00000000e+00, 1.00000000e+00, 2.00000000e+00, 3.00000000e+00, 4.00000000e+00, 5.00000000e+00, 6.00000000e+00, 7.00000000e+00, 8.00000000e+00, 9.00000000e+00])
Q:Scalar张量和高维张量运算后数据类型与PyTorch不一致?:
A: 如下用例所示,PyTorch中Scalar张量和高维张量运算后数据类型以高维张量数据类型为准。由于机制差异,MindTorch中Scalar张量和高维张量运算后数据类型向上转换:
>>> import torch
>>> import mindtorch.torch as mstorch
>>> a = torch.tensor(1).to(torch.float32)
>>> b = torch.tensor([2., 3.]).to(torch.float16)
>>> a + b
tensor([3., 4.], dtype=torch.float16)
>>> c = mstorch.tensor(1).to(mstorch.float32)
>>> d = mstorch.tensor([2., 3.]).to(mstorch.float16)
>>> c + d
Tensor(shape=[2], dtype=Float32, value= [ 3.00000000e+00, 4.00000000e+00])
Q: 接口报错不支持list入参类型:
A:PyTorch部分接口的入参在官网中显示只支持tuple类型,但实际部分场景用户传入list也能正常处理。针对这类隐藏用法,MindTorch已识别并适配部分接口,但可能存在遗漏情况,用户可自行转换成tuple后传入,或通过issue反馈给我们。